Performance Model Kickoff
By: Thang Tran, CTO Simplex Micro We have started a joint development project with CircuitSutra Technologies, headquartered in India, to develop a performance model of our RISC-V scalar/vector processor core. This blog series will showcase the features and benefits of the model as the model moves from specification to completion. The objective is straightforward. We […]

Silicon Catalyst Announces Seven Newly Admitted Companies to Semiconductor Industry Accelerator

Silicon Valley, California – November 5, 2025 – Silicon Catalyst, the only accelerator focused on the global semiconductor industry, including Chips, Chiplets, Materials, IP and Silicon fabrication-based Photonics, MEMS, Sensors, Life Science and Quantum, announces the admission of seven companies into the semiconductor industry’s highly acclaimed program. The new Portfolio Companies include:
· Athos Silicon – Innovative chiplet-based compute platform
· Chevin Technology – Quantum ready, hardware-based security solution
· Diamond Quanta – Breakthrough engineered diamond platform
· MoRF – Developing RF and photonic tunable chiplets
· SensTek Diagnostics – Nextgen solid-state sensor for molecular diagnostics
· Simplex Micro – Cutting-edge RISC-V CPU/Vector/Matrix IP
· WiConnectGlobal – Co-packaged solutions for high-speed photonic interconnect
Nick Kepler, Silicon Catalyst COO:
“We’ve created a comprehensive ecosystem for semiconductor startups that lowers the capital expenses associated with the design and fabrication of silicon-based integrated circuits (ICs), sensors, and microelectromechanical systems (MEMS) devices, including advanced design tools and services from a comprehensive network of In-Kind Partners (IKPs). The startup Portfolio Companies in our bespoke 24-month program leverage IKP tools and services, including design tools, simulation software, design services, foundry PDK access and MPW runs, test program development, tester access, banking and legal services. Additionally, our world-class network of advisors and investors further facilitates their journey from idea through prototype toward volume production. We look forward to working closely with these organizations as they grow their businesses.”
Simplex Micro
Austin, Texas
Thang Tran, CEO
thang@simplexmicro.com
At Simplex Micro, we embody the principle of “simple execution.” We strive to simplify the complex and our cutting-edge RISC-V CPU/Vector/Matrix IP delivers unified, spec-compliant performance across the latest RISC-V standards. This architecture enables low-power, deterministic, time-based execution across a spectrum of workloads—whether scalar-dominant to vector-rich to matrix-heavy—while maintaining robust latency tolerance for real-world deployment.

Moving Past Speculation
How deterministic CPUs deliver predictable AI performance
Thang’s work at Simplex Micro is redefining what’s possible in AI hardware. This piece dives deep into how deterministic, time-based execution can outperform speculative architectures—especially under real-world latency. It’s not just theory: the benchmarks speak for themselves.
In internal tests, the Simplex VPU achieved 400 GFLOPS sustained throughput on 16-bit matrix multiplication, outperforming many mid-range accelerators that only disclose peak performance under ideal conditions. It delivered 16× better performance at 100-cycle memory latency compared to speculative out-of-order baselines, highlighting its resilience where other architectures degrade by 2–5× or more. The VPU also achieved a 50% reduction in silicon area and power consumption versus conventional vector designs, making it ideal for edge, HPC, and energy-sensitive deployments. These gains result from eliminating speculative overhead and redundant memory traffic, ensuring every instruction contributes directly to execution without rollbacks or wasted bandwidth.
If you care about energy efficiency, predictable performance, and the future of RISC-V, this is worth a read.
*Simplex Micro’s target is licensing of the vector processor and multi-threaded CPU and not stand-alone CPU*
By Dr. Thang Minh Tran, CEO/CTO Simplex Micro | NOVEMBER 2ND, 2025
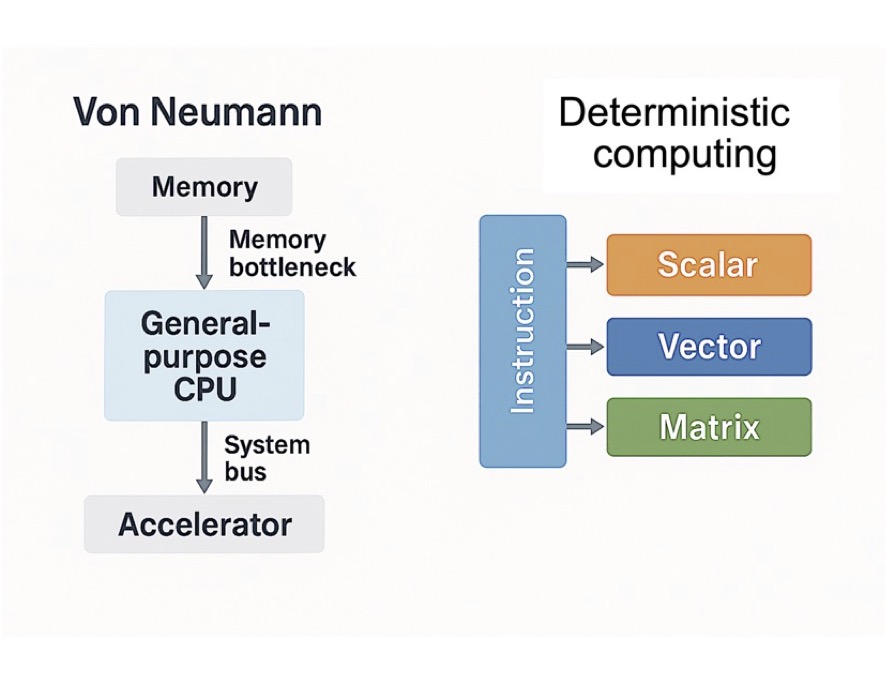
Beyond Von Neumann
Toward a unified deterministic architecture
For over 50 years, our industry has been bound by the Von Neumann model — from CPUs and GPUs to specialized AI accelerators. Even as we added complexity through speculation, prediction, and out-of-order execution, performance came at the cost of efficiency and predictability.
In my new VentureBeat article, I introduce a new paradigm: Deterministic Execution — a cycle-accurate approach that eliminates speculation and unifies scalar, vector, and matrix compute under one deterministic scheduler.
By orchestrating compute and memory with precise timing, we can achieve higher throughput, lower power, and simpler hardware — a foundation for the next generation of AI and general-purpose processors.
By Dr. Thang Minh Tran, CEO/CTO Simplex Micro | OCTOBER 4TH, 2025
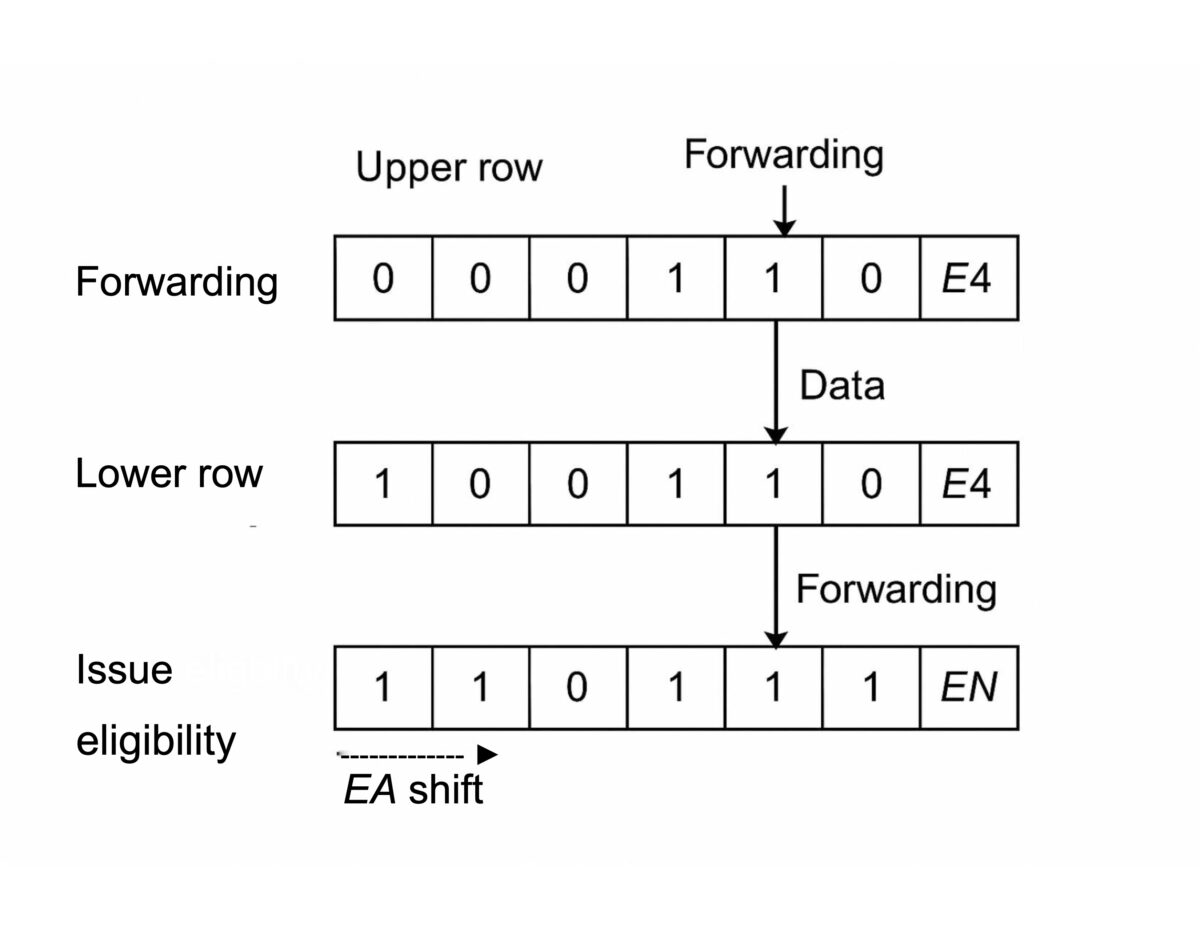
Rethinking Scoreboards
A path forward for ai-era cpus
In the pursuit of higher performance and tighter power budgets, AI accelerators are pushing microarchitectures to their limits. Deep pipelines and speculative execution bring power penalties and complexity—but what if we’ve been overlooking a simpler, more elegant solution?
In my latest article on SemiWiki, I explore how a refined scoreboard architecture—rooted in classic CPU design—can offer a scalable, energy-efficient path forward. By enabling precise instruction scheduling and eliminating speculative overhead, we can unlock instruction-level parallelism without the usual cost.
By Dr. Thang Minh Tran, CEO/CTO Simplex Micro | July 1st, 2025
Speculative Execution
Rethinking the approach to CPU scheduling in ai data centers
In this latest SemiWiki article from Simplex Micro’s CEO/CTO Thang Tran, he explores how predictive execution can replace speculative execution in modern data centers, offering a more efficient, cost-effective solution. This shift not only reduces power consumption and silicon overhead but also eliminates the need for expensive HBM, transforming the future of AI infrastructure.
As AI workloads continue to grow, rethinking the traditional speculative execution model is essential for staying competitive. In his article, Thang dives into how predictive execution can streamline CPU scheduling, helping data centers scale more efficiently and sustainably.
by Jonah McLeod | may 7th, 2025
Predictive Load Handling
Solving a quiet bottleneck in modern dsps
Memory stalls: the silent killer in DSPs for embedded AI.
When we talk performance, it’s easy to focus on MACs, vector width, or clock speed. But in the trenches of edge AI—voice, radar, low-power vision—it’s latency that quietly derails everything.
My latest article explores a persistent bottleneck most DSP toolchains overlook: non-cacheable memory and the precise timing demands it imposes.
Traditional approaches rely on deterministic scratchpads and TCM. But if the data isn’t there exactly when it’s needed? The pipeline stalls, IPC crashes, power is wasted.
Enter Predictive Load Handling—a technique that doesn’t try to guess what address will be accessed, but instead predicts when it will be available.
It’s a subtle shift with major implications for real-time inference.
by Jonah McLeod | April 17th, 2025
Even HBM Isn’t Fast Enough All the Time
why latency-tolerant architectures matter
in the age of ai supercomputing
High Bandwidth Memory (HBM) has become the defining enabler of modern AI accelerators.
From NVIDIA’s GB200 Ultra to AMD’s MI400, every new AI chip boasts faster and larger stacks of HBM, pushing memory bandwidth into the terabytes-per-second range. But beneath the impressive specs lies a less obvious truth: even HBM isn’t fast enough all the time. And for AI hardware designers, that insight could be the key to unlocking real performance.