

Last month we reported that the SimplEx Micro performance model had entered the validation phase, with Dhrystone running and correlation against RTL underway. Since then, the focus has shifted toward deeper verification, benchmark execution, and improving confidence in both the model and the underlying architecture.
Dhrystone now runs to completion on the performance model and remains the primary workload for scalar CPU correlation with RTL. The team is comparing execution traces, timing behavior, and instruction flow between the two environments to ensure that the model accurately reflects hardware behavior. Correlation scripts are being developed to automate this process and accelerate future validation efforts.
On the vector side, a significant milestone was achieved with the successful completion of the Matrix Multiply benchmark. This workload heavily exercises the vector engine’s floating-point multiply-accumulate datapath and serves as an important validation step before larger AI workloads are introduced. After resolving an interface-related issue in the VPU model, the benchmark completed successfully. Correlation with RTL is now underway.
The benchmark strategy remains focused on four representative workloads:
- Dhrystone — scalar CPU validation and RTL correlation
- Matrix Multiply — vector execution and FMAC validation
- TinyML — embedded AI and edge-device workloads
- Qwen — large language model inference analysis
Together, these benchmarks span traditional CPU processing, vector acceleration, embedded machine learning, and modern transformer-based AI inference.
The next major milestone will be the introduction of TinyML and Qwen into the validation flow. These workloads will provide visibility into how the architecture behaves under realistic AI applications while extending correlation efforts beyond synthetic benchmark kernels.
At the same time, planning has begun for Stage 2 of the performance model. Stage 1 established a functioning CPU/VPU architecture and a working correlation framework. Stage 2 will introduce more realistic memory-system behavior, including cache hierarchy enhancements, sensitivity analysis, and evaluation of practical queue sizes under varying workload conditions. These additions will help the team understand not only how the architecture functions, but how it scales as workloads become increasingly memory-intensive.
The project has now moved well beyond model construction. Benchmarks are running to completion. Starting from scratch to successfully run Dhrystone and Matrix Multiplication in about 3 months. This is a simple-execution performance model which adapted well with SimplEx CPU/VPU and also with any CPU/VPU. Correlation is uncovering timing differences and improving model fidelity. Most importantly, the architecture is beginning to produce measurable results that can be validated against RTL and eventually used to guide future design decisions.
Visualization sample, the number of cycles can be millions
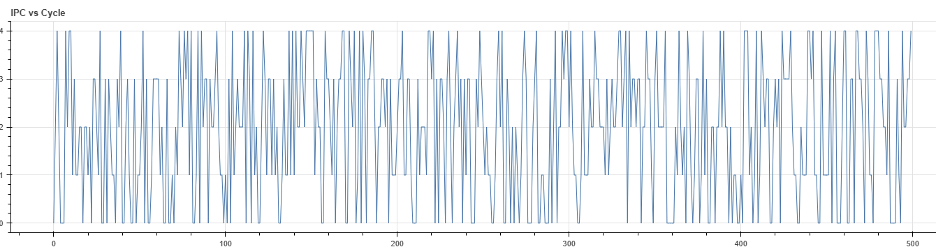
With zoom-in capability:
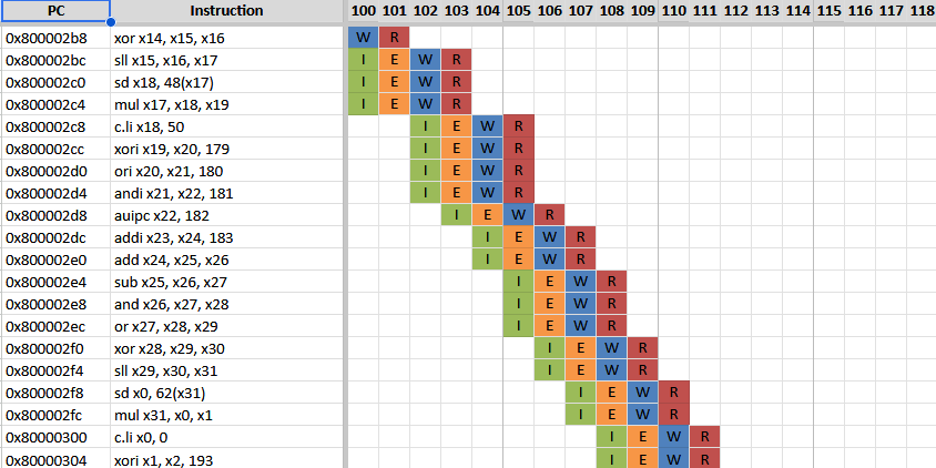
The focus remains unchanged:
Correlate. Verify. Measure. Learn.
By Thang Tran, CTO, SimplEx Micro
No responses yet